// 06 · IN PRODUCTION
THE SYSTEM
AT WORK
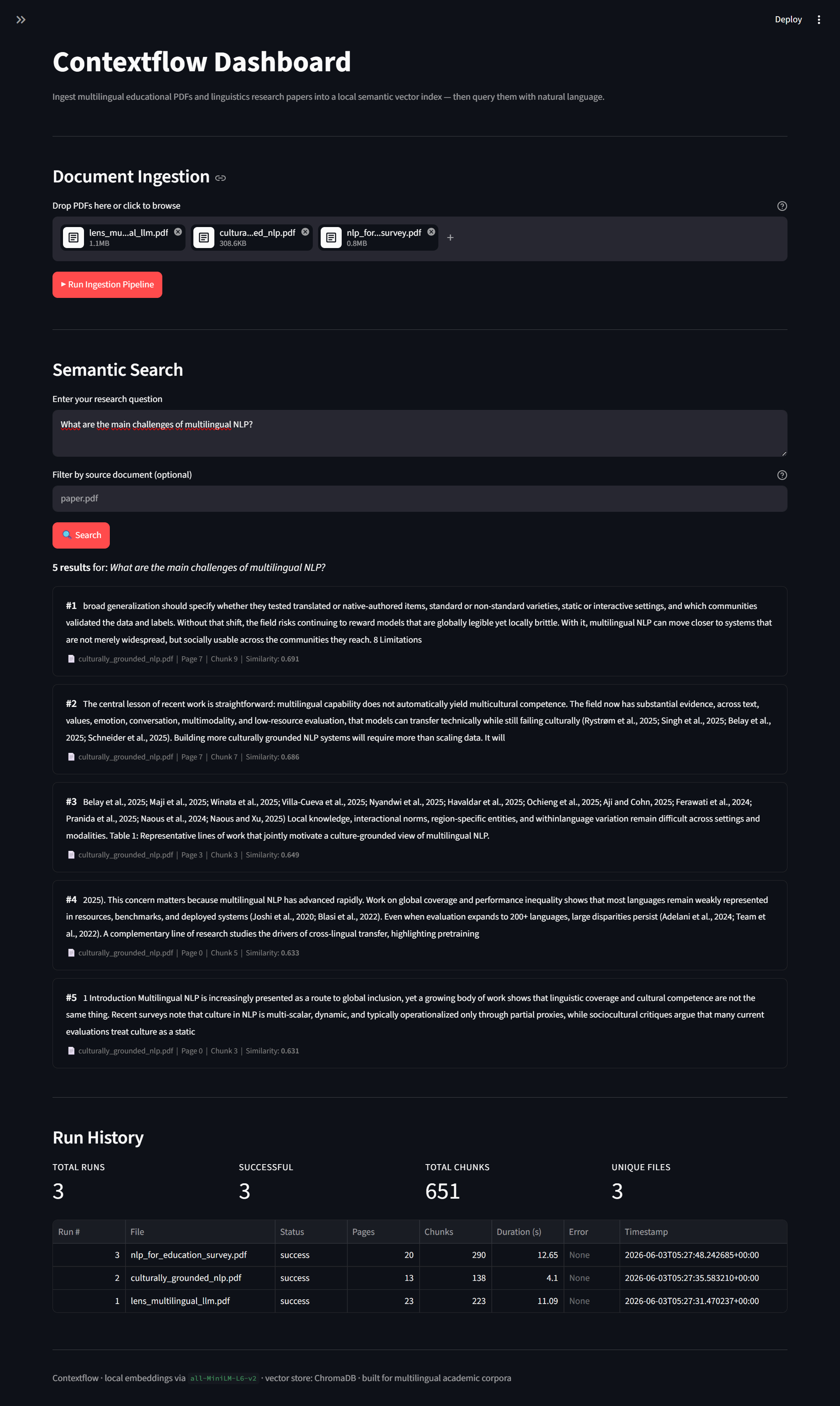
// STREAMLIT RAG DASHBOARD · SEMANTIC SEARCH · RUN HISTORY
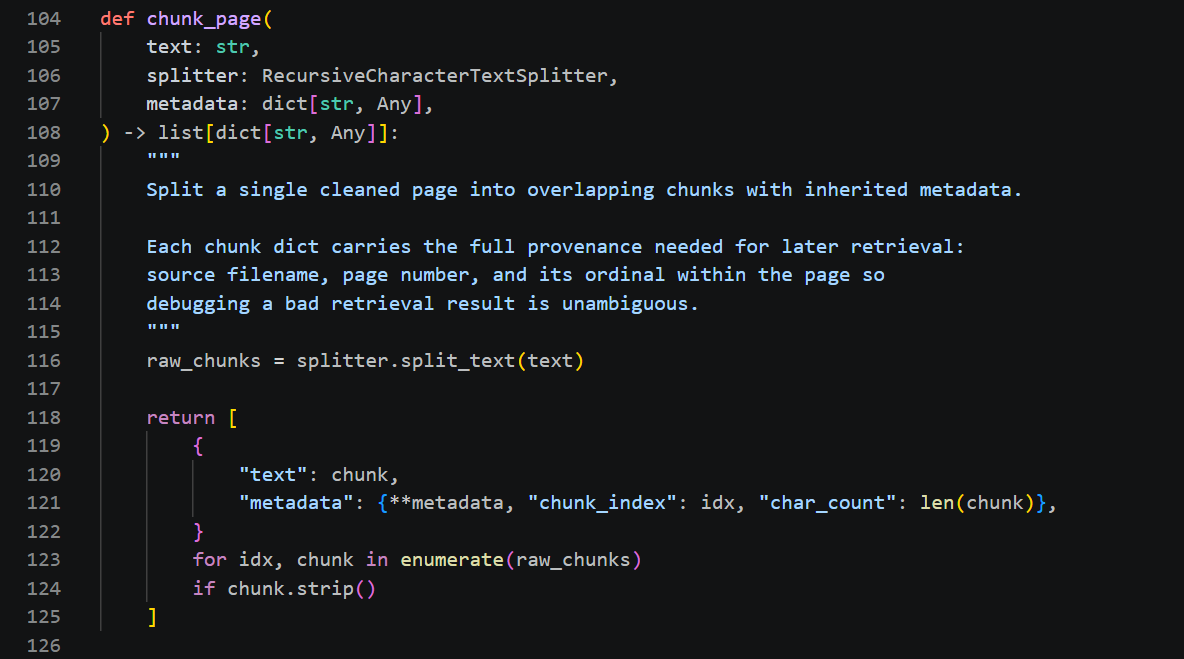
// DATA NORMALIZATION · UNICODE REPAIR · IPA RECOVERY · HYPHENATION JOIN
Multilingual PDF to semantic vector ETL. Drop documents in, ask in plain English, get ranked results with exact page provenance in under two seconds.
The standard approach to a library of multilingual academic PDFs is to open them one by one and press Ctrl+F. That is not search. That is manual labor disguised as a workflow.
The harder version: LaTeX-compiled linguistics papers with IPA symbols, UTF-8 encoding edge cases, inconsistent whitespace conventions, and words split across lines at the PDF page-content level. Naive pipelines silently corrupt these. They extract garbage and never report it.
ContextFlow was built for that harder case. A pipeline that handles mis-decoded IPA glyphs and hyphenated linebreaks correctly handles everything else by default.
The same document always produces the same chunk IDs. Re-running the pipeline performs an upsert, never a duplicate. The mechanism that makes ContextFlow safe to re-trigger without consequence.
def _stable_chunk_id(source: str, page: int, chunk_index: int) -> str: # Same inputs always produce the same ID. # Re-running on the same document: upsert, never a duplicate. raw = f"{source}::p{page}::c{chunk_index}" return hashlib.sha256(raw.encode()).hexdigest()[:16] # result: "a3f292b1c0e4d7f8" # deterministic across machines, restarts, and reruns