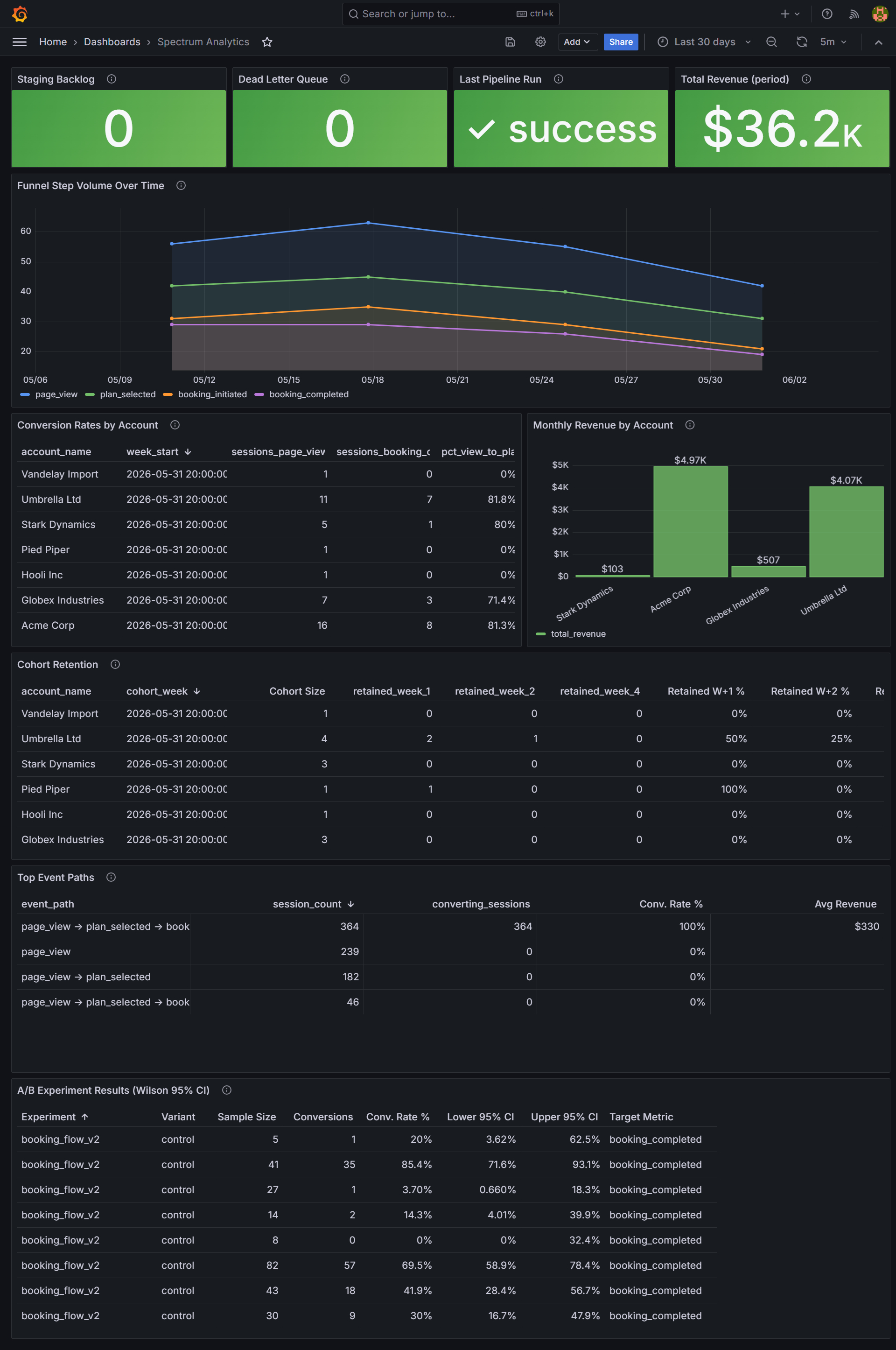
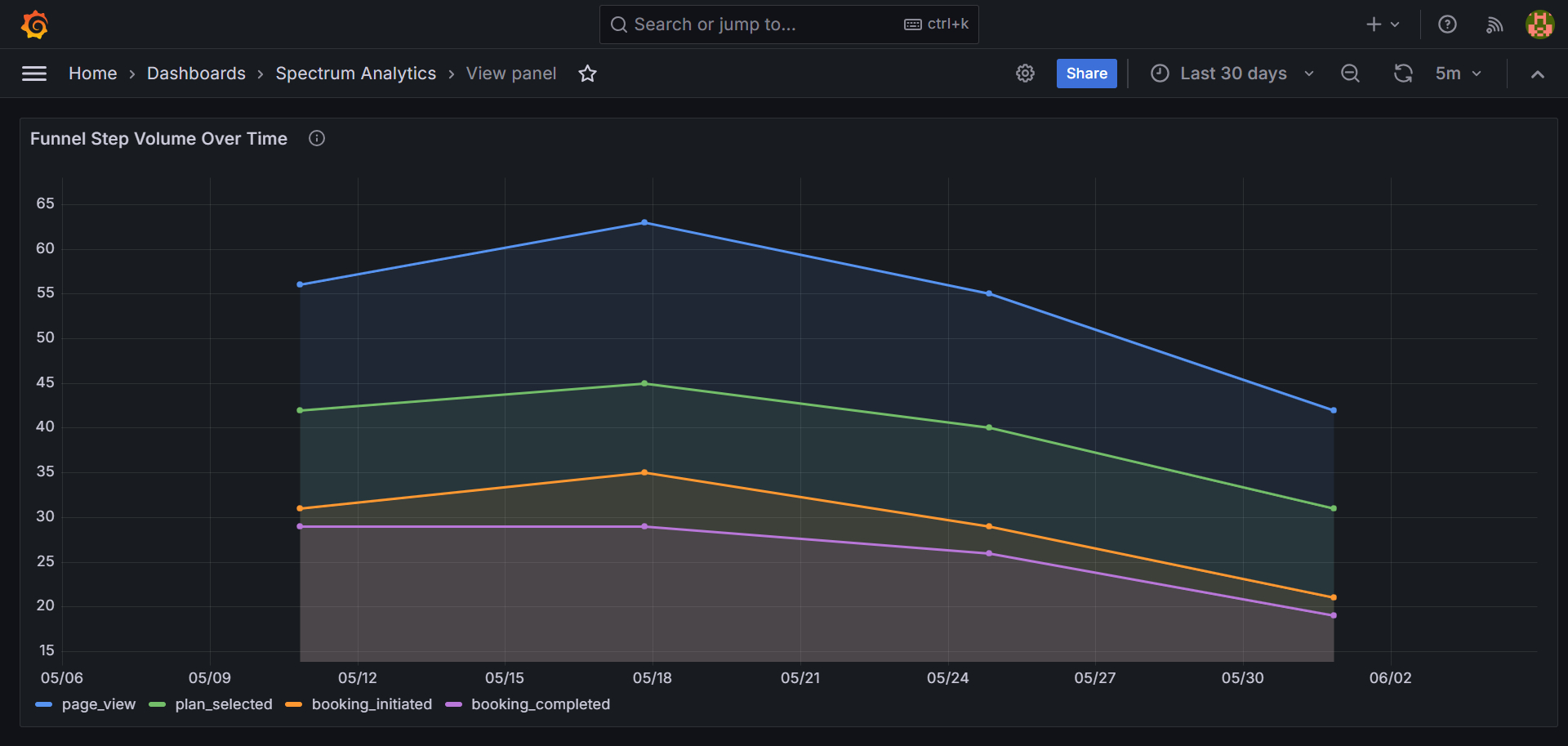
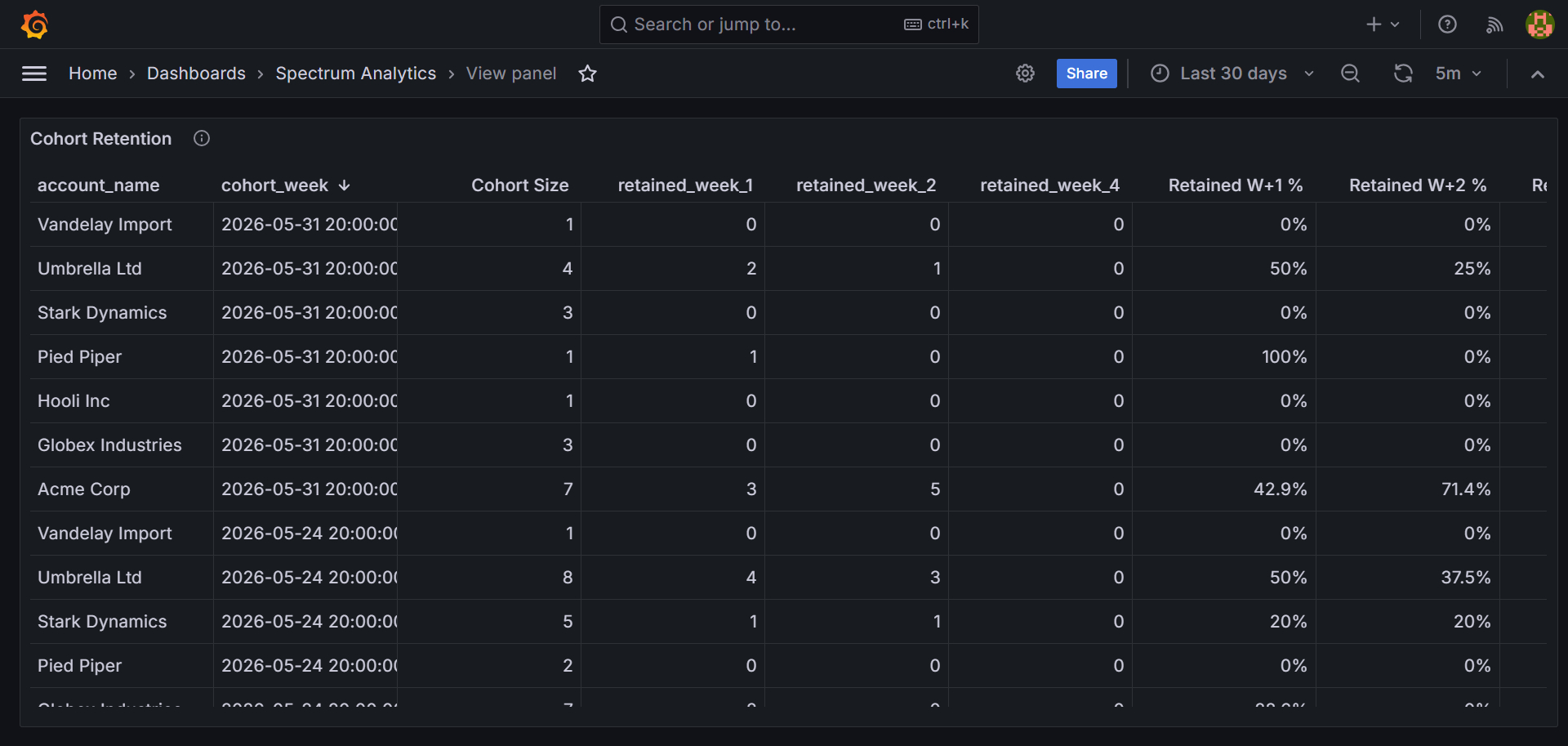
Product analytics at any meaningful scale is a queue problem. Events arrive concurrently from multiple sources. Workers must claim and process them without overlap. If two workers claim the same event, the metric counts are wrong. If a worker crashes mid-claim, the event cannot be lost.
Most systems solve this with application-level locks or a message broker. Spectrum solves it at the database level using PostgreSQL's FOR UPDATE SKIP LOCKED. Each worker atomically claims one row, skipping any row another worker has locked. No external coordinator. No message broker for the hot path.
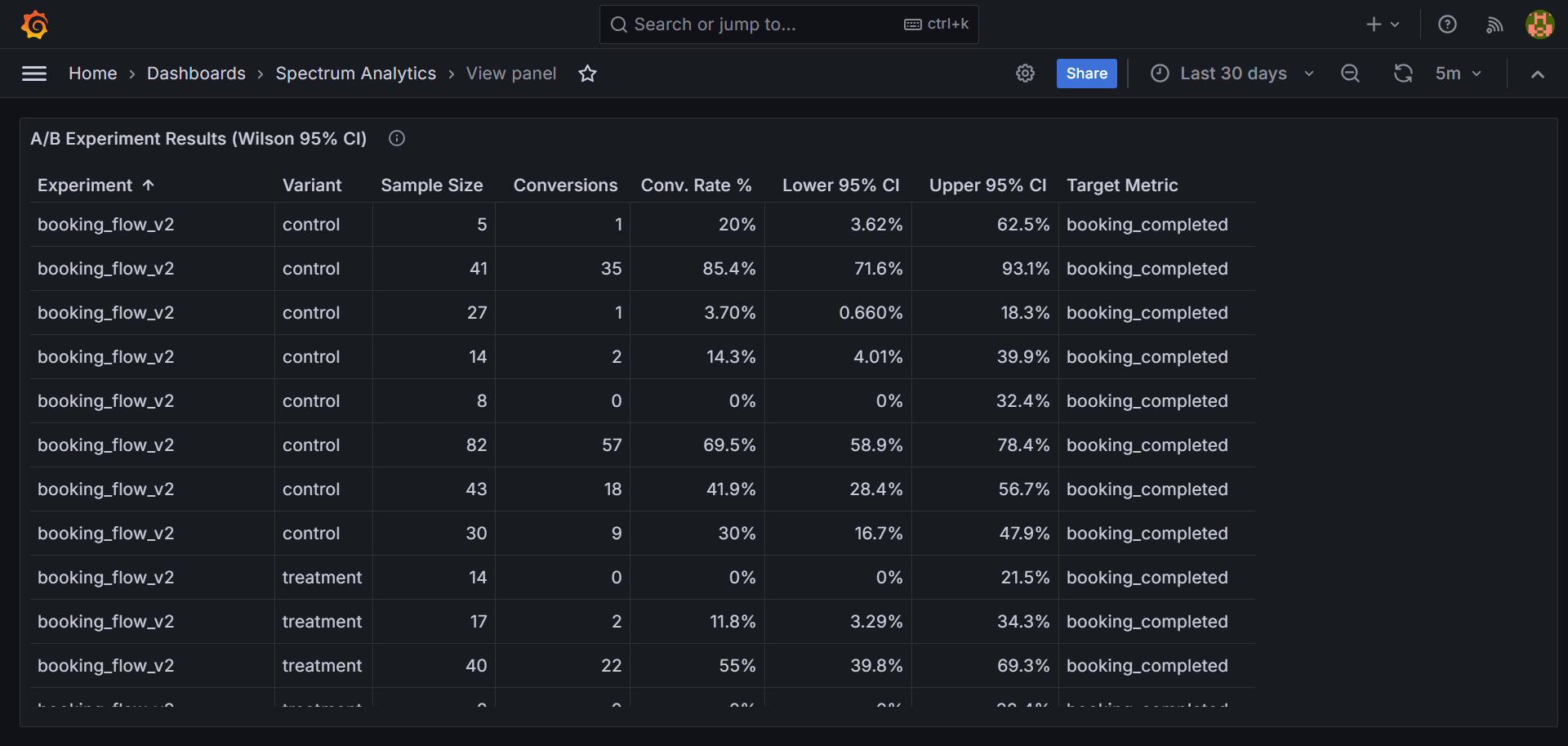
The downstream requirement was a proper data warehouse structure for analytical queries. Not a log store. A star schema with dimension tables, a central fact table, and the ability to run cohort and experiment queries directly in SQL without ETL preprocessing.