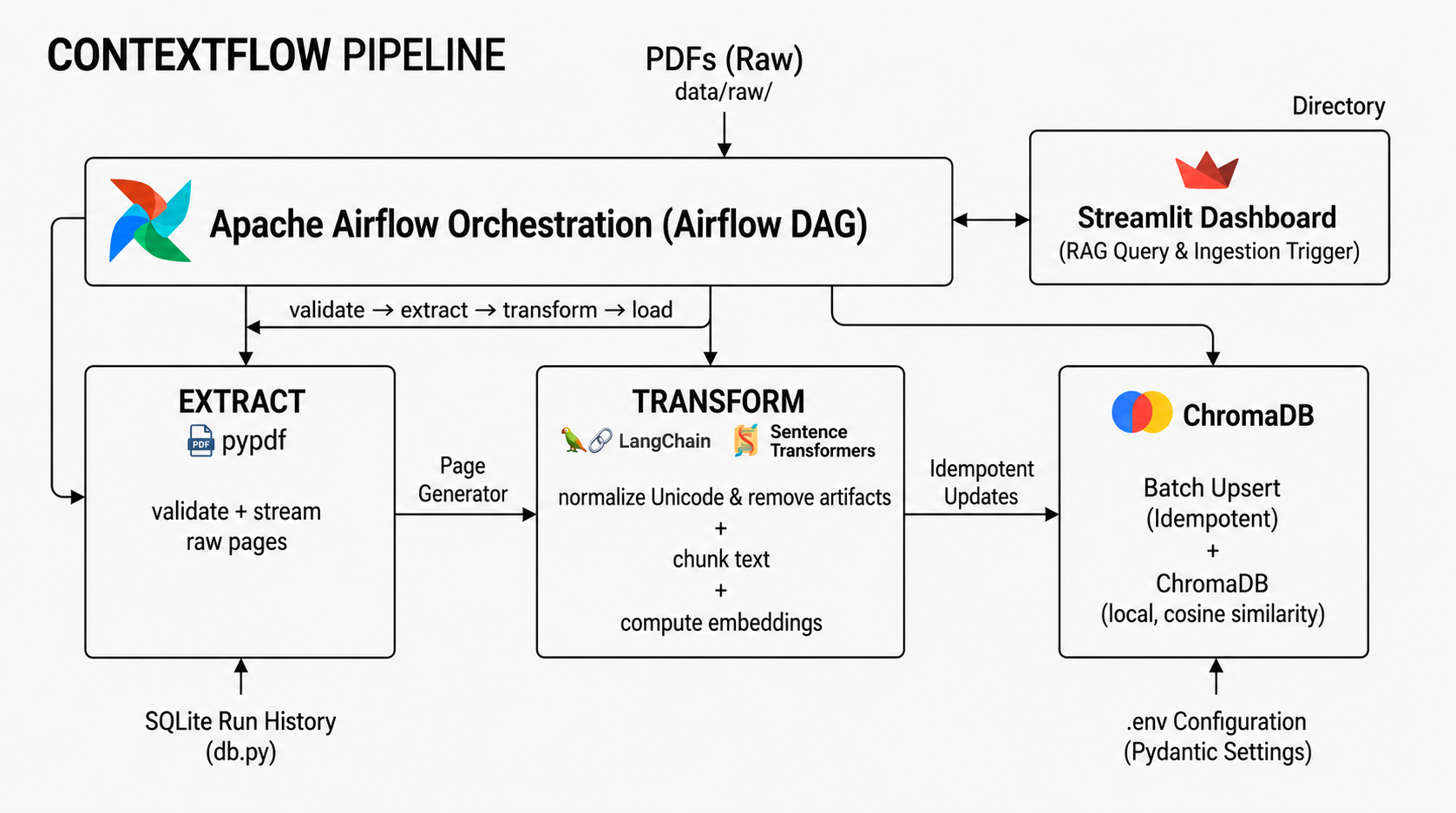
Embeddings work on chunks, not whole documents, so how you split the text directly shapes what the search can find. ContextFlow chunks with a structure-aware splitter and stamps every chunk with where it came from, so results are both accurate and citable.
// 01 — STRUCTURE-AWARE SPLITTING
A naive splitter cuts every N characters, slicing through sentences and entities. ContextFlow uses RecursiveCharacterTextSplitter with a hierarchy of separators. It tries to break on the most natural boundary available, in order:
separators = ["\n\n", "\n", ". ", "! ", "? ", " ", ""]
chunk_size = 512 # ~2–3 academic sentences
chunk_overlap = 64 # 12.5%It prefers paragraph breaks, then line breaks, then sentence ends, falling back to spaces only when it must. Chunks land on meaningful boundaries instead of mid-thought.
// 02 — WHY OVERLAP
Each chunk repeats the last 64 characters of the previous one. That overlap preserves cross-boundary context: a named entity or clause that straddles a split still appears whole in one of the two chunks. Without overlap, the concept that happens to fall on a boundary is findable in neither.
// 03 — PROVENANCE ON EVERY CHUNK
Every chunk carries metadata: source, page_number, chunk_index, char_count. This is what lets a search result say “page 14 of paper.pdf” instead of just handing back text. Provenance is what makes retrieval trustworthy: you can follow any answer back to the exact page it came from and verify it.
TAKEAWAYS
- Chunk on natural boundaries, not fixed offsets. A separator hierarchy keeps sentences and entities intact, which keeps embeddings meaningful.
- Overlap (~10–15%) saves the concepts that fall on a split. It’s cheap insurance against boundary blindness.
- Carry provenance through every chunk. A retrieval system you can’t cite is a retrieval system you can’t trust.
NEXT
- Build log 04: 384 dimensions, zero API cost: local embeddings.
