A PDF is a layout format, not a text format. Pulling clean text out of one, especially a LaTeX-compiled linguistics paper full of IPA and accents, is most of the battle in a retrieval pipeline. Garbage text produces garbage embeddings, and the search is only as good as the text underneath it.
// 01 — RECOVERING MIS-DECODED CHARACTERS
pypdf sometimes hands back IPA symbols and accented letters that were mis-decoded at the byte level. _decode_page_text() recovers them with a latin-1 → UTF-8 re-encode trick, reinterpreting the bytes under the correct encoding so ʃ, é, and friends come back intact instead of as mojibake.
// 02 — THE CLEANING ORDER
clean_text() applies six transformations, and the order is load-bearing: each step assumes the previous one ran:
- Expand ligatures:
fi → fi,fl → fl,ff/ffi/ffl,st → st. PDF typesetting artifacts. - NFC normalize: collapse combining diacritics to precomposed form, so
é(e + ◌́) equalsé(single codepoint). Without this, two visually identical strings embed differently. - Strip Unicode spaces: remove non-breaking and zero-width spaces PDF renderers inject.
- Join hyphenated line-breaks:
seman-\ntic → semantic, the LaTeX line-wrap artifact. - Collapse excess newlines: 3+ newlines → 2, preserving paragraph breaks.
- Strip trailing whitespace per line: column layouts pad lines to page width with spaces.
// 03 — WHY ORDER MATTERS
Run NFC normalization before ligature expansion and you can normalize a ligature into a form the expander no longer recognizes. Join line-breaks before stripping the zero-width spaces and the hyphen match can miss. Each step is cheap; the sequence is the design. Get it wrong and the corruption is subtle: the text looks fine to a human and embeds wrong.
TAKEAWAYS
- Text extraction quality is retrieval quality. Bad characters in means bad vectors in means bad search out. Clean aggressively before embedding.
- Unicode normalization (NFC) is not optional for multilingual text: visually identical strings must become byte-identical or they won’t match.
- When transformations interact, the order is part of the algorithm. Document it, test it, don’t reshuffle it casually.
NEXT
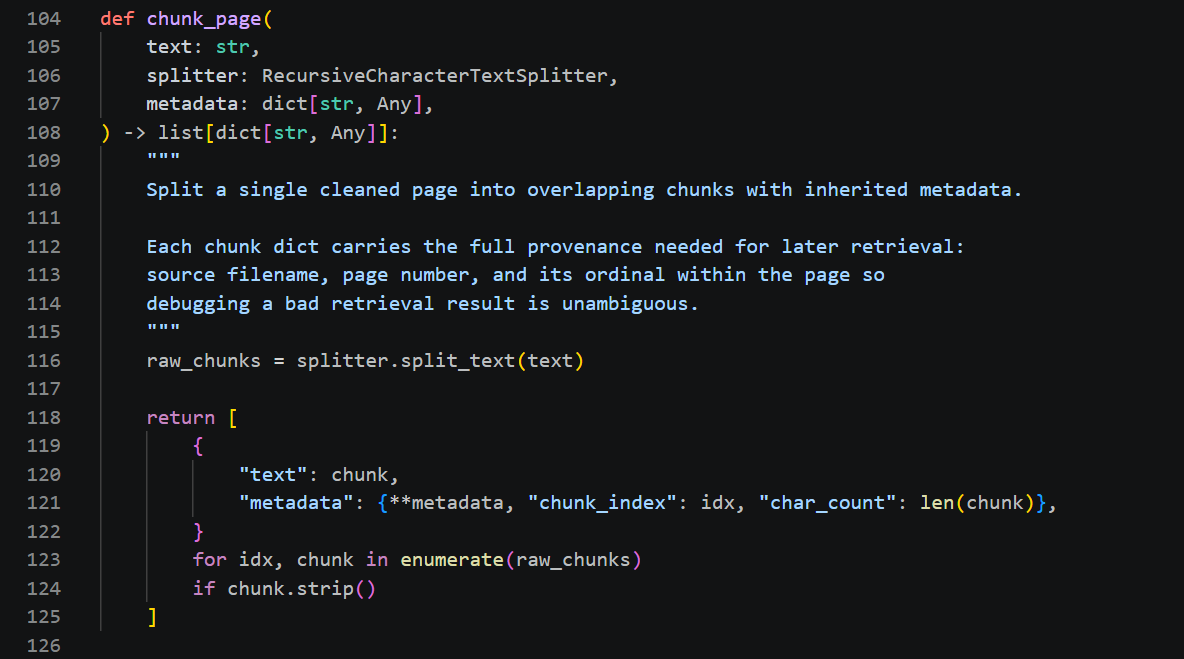
- Build log 03: chunking with provenance: 512 chars, 64 overlap, full lineage.
