Ctrl+F finds keywords. It can’t find an idea phrased differently than you searched for it. ContextFlow is an ETL pipeline that makes a document library searchable by meaning: drop in 100 PDFs, ask “what phonological features distinguish tonal languages?”, and get ranked passages from across the whole corpus in under two seconds, each with a similarity score and the exact page it came from.
This is the first entry in its codex: what it does, and why it’s built for the hard case.
// 01 — THE GAP
Keyword search matches strings. Semantic search matches concepts, by turning text into vectors whose distance reflects meaning. Two passages about the same idea land near each other in vector space even if they share no words. That’s the difference between “find the document containing this phrase” and “find what’s relevant to this question.”
// 02 — THE PIPELINE
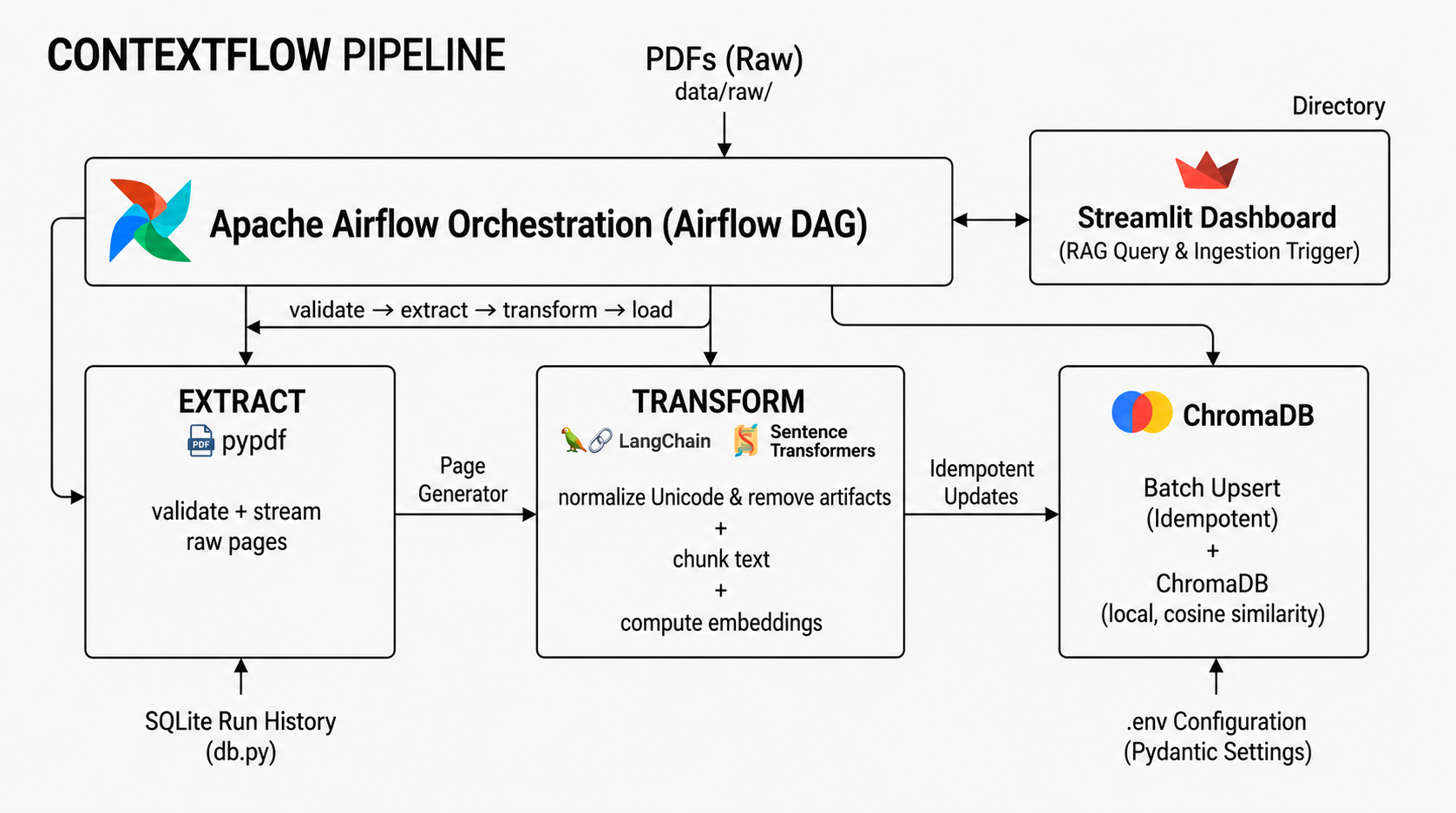
Five stages, extract → transform → load → log → query:
PDFs → extract (stream pages, fix encoding)
→ transform (clean unicode · chunk 512/64 · embed 384-dim)
→ load (deterministic IDs · upsert into ChromaDB)
→ log (one SQLite row per run)
→ query (cosine similarity → ranked results + provenance)It’s fully idempotent: re-running on the same document upserts, never duplicates, and it runs entirely local. The embedding model, the vector store, and the audit log all live on your machine, at zero API cost.
// 03 — BUILT FOR THE HARD CASE
The target isn’t clean corporate PDFs. It’s multilingual academic papers compiled from LaTeX: linguistics texts full of IPA symbols, accented characters, ligatures, and the UTF-8 edge cases that quietly corrupt naive pipelines. Getting those right is most of the work, and it’s where the next few entries go. Validated end-to-end on real arXiv papers: 56 pages, 651 chunks, top-1 similarity 0.802, 60/60 tests green.
TAKEAWAYS
- Semantic search retrieves by meaning, not string match. It finds the relevant passage even when it shares no words with your query.
- A retrieval pipeline is ordinary ETL with an embedding step: extract, clean, chunk, embed, load, query.
- Running fully local (model + vector store + log) means zero API cost and zero data leaving your machine, which matters for private corpora.
NEXT
- Build log 02: cleaning multilingual PDFs: ligatures, IPA, and broken unicode.
