
A few months ago Microsoft dropped MarkItDown on GitHub.
If you missed it: it converts PDF, DOCX, PPTX, and a few other formats into clean Markdown. Specifically to make documents cheaper and cleaner to feed into LLMs. It spread through the data engineering community fast.
I saw it the day it trended. I understood exactly what problem it was solving.
I also understood it wasn’t what I was going to build.
The problem is real
Every time you drop a raw document into an AI context window, you’re not feeding it the content. You’re feeding it the content plus every piece of formatting noise the file ever accumulated: headers that repeat on every page, style tags, navigation menus, page numbers, inline characters that mean nothing to a language model but cost tokens on every request. The model processes all of it. You pay for all of it. The signal-to-noise ratio drops, and the output quality goes with it.
MarkItDown is a direct answer to that. Strip the noise, convert to Markdown, give the model something it can actually work with.
I’d been running into this exact problem while building Phronis and ContextFlow. Every time I needed to put a document into an agent context, I was doing some version of this manually. So yes: I understood the problem, I agreed with the approach.
What I didn’t agree with was the delivery format.
pip install is not a product
MarkItDown is a Python library. pip install markitdown. You run it in a script.
That’s fine if you’re a developer building a pipeline. It’s not fine if you want to hand a URL to someone and say “use this.” It’s not fine if you want to process a document on a machine without Python. It’s not fine if the person on the other end doesn’t know what a virtual environment is.
I wanted something with a URL. A tool you open in a browser, drop a file in, get clean Markdown back, and copy it wherever you need it. No install. No dependency. No setup. Deployable on a free tier in ten minutes.
That tool didn’t exist. So I built it.
Why JavaScript
The Python assumption for document processing is reflexive. There’s a decade of tooling: PyMuPDF, pdfplumber, python-docx, BeautifulSoup. The ecosystem is real and it’s good.
But I had a different constraint. I wasn’t building a script. I was building a web tool with a real UI, a design system, a gate, and a specific deployment target. That shifts the calculation.
If the frontend is HTML, CSS, and JavaScript, and the backend needs to serve those files, handle file uploads, talk to Resend, and deploy as a persistent web service, then Python gets you the document processing and makes everything else harder. JavaScript gets you the document processing AND the rest of the stack in one language, one repo, one deployment.
You don’t pick the tool for the hardest part of the problem. You pick the tool that makes the whole thing coherent.
I built the frontend in plain HTML, CSS, and JavaScript. No framework. Same Terminal Schema design system as frogwebp.com: same palette, same typography, same motion. That level of consistency isn’t achievable through Streamlit without fighting it for every pixel. Building it right from the start is less work than hacking around a tool that was never meant to be a product.
For the server I chose Fastify. It’s faster than Express under load and its plugin architecture handles multipart file uploads cleanly. The whole backend is three route files and four processor modules.
How the conversion pipeline works
The entry point is a single route handler that detects file type from both the MIME type and the extension. Browsers are inconsistent about MIME, so checking only one would miss valid files.
PDF: pdfjs-dist running in Node without a browser. Four flags matter: disableFontFace, disableAutoFetch, useWorkerFetch: false, and isEvalSupported: false. Without them, pdf.js tries to fetch remote fonts and spawn browser-style workers. Both fail silently in Node and give you empty output or hanging requests.
Text extraction happens page by page. Each page returns a flat list of text items with X/Y coordinates. Lines don’t exist in PDF format at the data level; they’re reconstructed from Y-coordinates: items within 5 units of the same Y value go on the same line. After each page, page.cleanup() releases the page resources. Then pdf.destroy() at the end. For large documents, skipping this holds decoded page data in memory across the whole document.
DOCX: mammoth converts to HTML first, then the HTML goes through the same processor used for native HTML uploads. mammoth’s HTML output preserves the semantic structure of the Word document far better than any direct DOCX-to-Markdown path would. Two steps, but worth it.
HTML: A custom scraper strips tags and converts structure. Navigation menus, scripts, styles, and everything inside head are dropped before conversion starts.
The cleaner
Every format gets a post-processing pass. This is where most of the noise reduction actually happens.
For PDFs:
- Hyphenation repair. PDFs split words across lines at the character level. “impor-\ntant” becomes “important.” One regex, whole document.
- Page number stripping. Standalone numbers on their own lines and “Page N of M” patterns get removed.
- Repeated block detection. Any text block longer than 8 characters that appears three or more times is a header or footer. Stripped. This handles the documents where a company name or confidentiality notice shows up on every single page.
For HTML:
- Navigation noise detection. Four or more consecutive Markdown links in a row is a nav menu that survived the conversion. Removed.
Both formats get whitespace normalization and heading normalization: if a document has no H1 but has H2 headings, everything moves up a level so the model gets a proper hierarchy.
The output stats come after all of this. Noise percentage is (input size - output size) / input size. Token estimate uses the 4-characters-per-token approximation, which is close enough for a display metric.
The gate
One free conversion. After that, it asks for an email.
This isn’t paywalling. The tool is free. The gate exists because email is the only durable signal I have from people who find it useful. The Corpus gate and the frogwebp newsletter share the same Resend audience. Everyone who uses the tool and wants to continue is someone I can reach when I ship the next thing.
Building a tool without any signal from who uses it is building blind. The gate costs thirty seconds. After submission, Resend adds the contact to the audience and sends a welcome email. The whole flow is one route handler.
Render, not Vercel
The main site deploys on Vercel. Corpus doesn’t.
Vercel serverless functions have a hard time ceiling: ten seconds on the default plan, sixty on Pro. A large PDF conversion can exceed that. And serverless functions are stateless, which creates friction for file upload flows where you want the request lifecycle to be predictable.
Render runs a persistent Node process. No cold start. The file lands, gets processed, and comes back. The free tier handles the traffic a new tool sees at launch without any configuration. The custom domain, corpus.frogwebp.com, was one CNAME record and five minutes of DNS propagation.
The architecture is intentionally split: Vercel for the static site, Render for the tool. Each platform does what it’s designed for. They don’t need to know about each other.
Use it
Corpus is free. No account, no rate limit after the gate, no paid tier.
If you’re building AI pipelines and need to feed documents into agent contexts without paying for formatting noise, it’s at corpus.frogwebp.com. PDF, DOCX, and HTML. Clean Markdown out. Under two seconds for most documents.
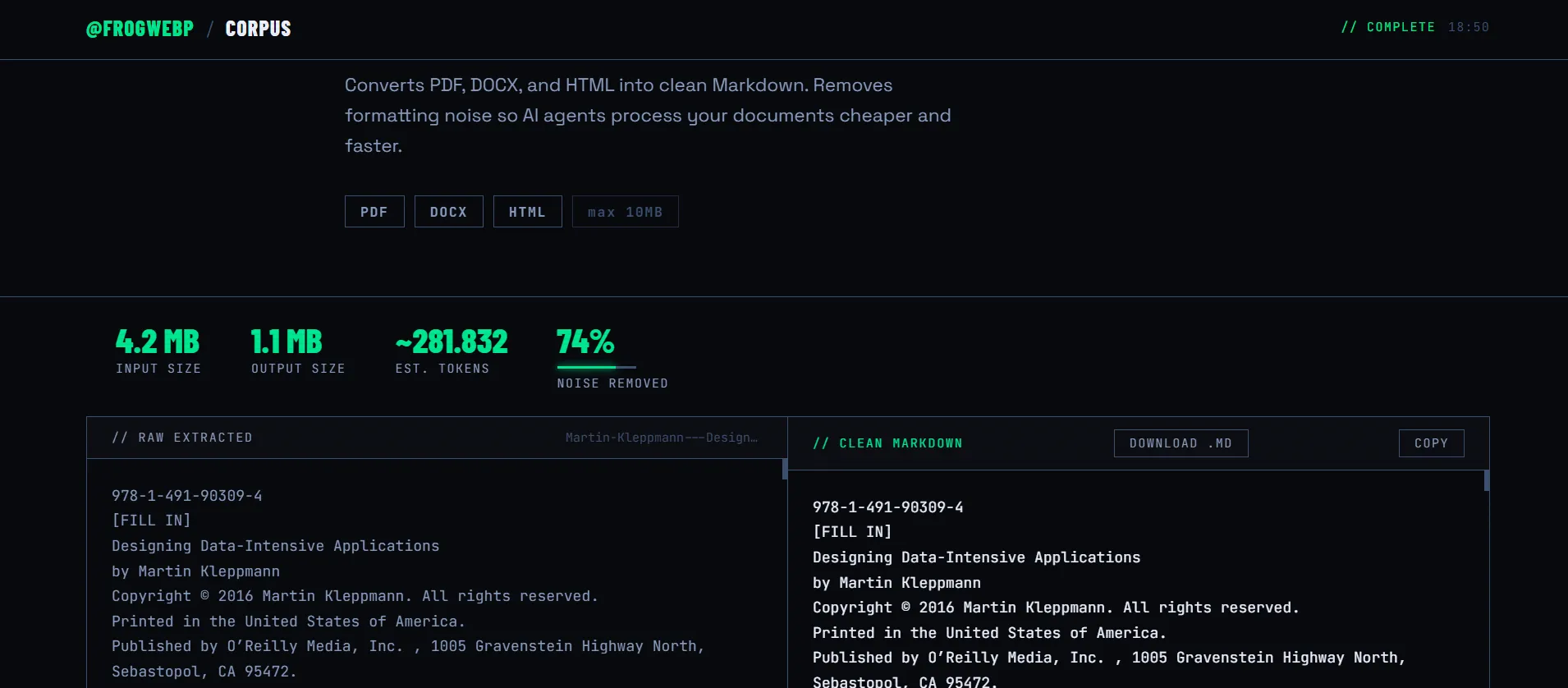
I tested it with Martin Kleppmann’s Designing Data-Intensive Applications — a 4.2 MB PDF. 1.1 MB of clean Markdown out. 74% noise removed.
If you build something with it, I want to know.
The thing I keep coming back to
MarkItDown is a good library. I use the same ideas. What I built isn’t a replacement for it.
It’s the answer to a different question: what does this look like as a tool instead of a dependency?
The answer is a URL.

Know what you’re building before you decide how. A library and a product solve the same problem in completely different ways, and the wrong choice at the start costs everything that follows. That’s not a criticism of MarkItDown. It’s a library. It should be a library. That’s exactly what it should be.
Corpus is the thing I wanted to exist and didn’t find.
