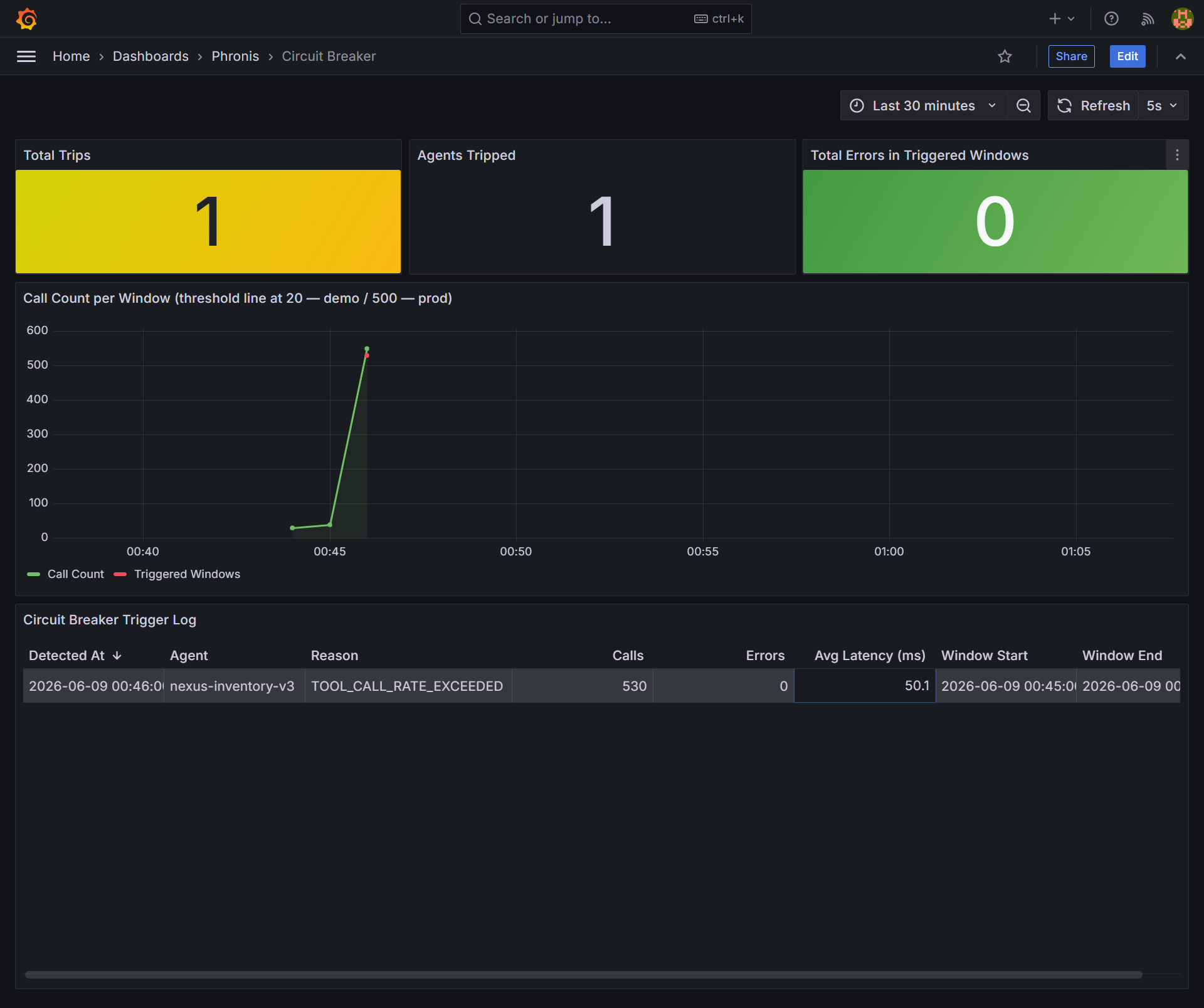
I’d start a fresh demo, and before a single agent had made a single call, the circuit breaker would already be tripped, citing a detection window from hours earlier. The system was halting an agent for something that happened in a previous session.
// 01 — THE SETUP
The demo runs three agents; Phase 1 is supposed to show them all healthy before Phase 2 introduces a misbehaving one. AlertExecutor consumes the phronis.alerts topic and trips breakers when alerts arrive.
// 02 — THE SYMPTOM
On a clean start, a breaker tripped immediately, and the circuit-breaker event showed a window_end timestamp from a previous demo run, not the current time. An agent was halted before it had done anything.
// 03 — THE CULPRIT
phronis.alerts has a 1-day retention policy. Alerts from yesterday’s demo were still sitting in the topic. When a new run’s AlertExecutor started consuming, it found those old alerts and replayed them into the fresh session, tripping breakers based on incidents that were over.
This is distinct from offset management (a separate bug about the consumer’s auto-commit). This one is about topic data surviving across sessions: the alerts were real, just stale, and nothing cleared them between runs.
// 04 — THE FIX
setup.ps1 now deletes and recreates phronis.alerts at the start of every run, flushing stale alerts before anything consumes them:
podman exec phronis-redpanda rpk topic delete phronis.alerts 2>&1 | Out-Null
# topic is recreated immediately afterThe rule that came out of it: always run setup.ps1 before a demo. Running the demo alone is insufficient if a prior session left alerts behind.
TAKEAWAYS
- Topic retention outlives your process. A consumer starting fresh will happily replay messages from previous runs unless you clear them or manage offsets deliberately.
- “Stale data replay” and “offset mismanagement” look identical from the outside (old events processed as new) but have different fixes: flushing the topic vs. committing offsets. Diagnose which.
- For demos and tests, make state-reset explicit and mandatory. Reproducibility dies when yesterday’s data leaks into today’s run.
NEXT
- Anomaly log: you can’t bind to a ClusterIP: Redpanda on Kubernetes.
