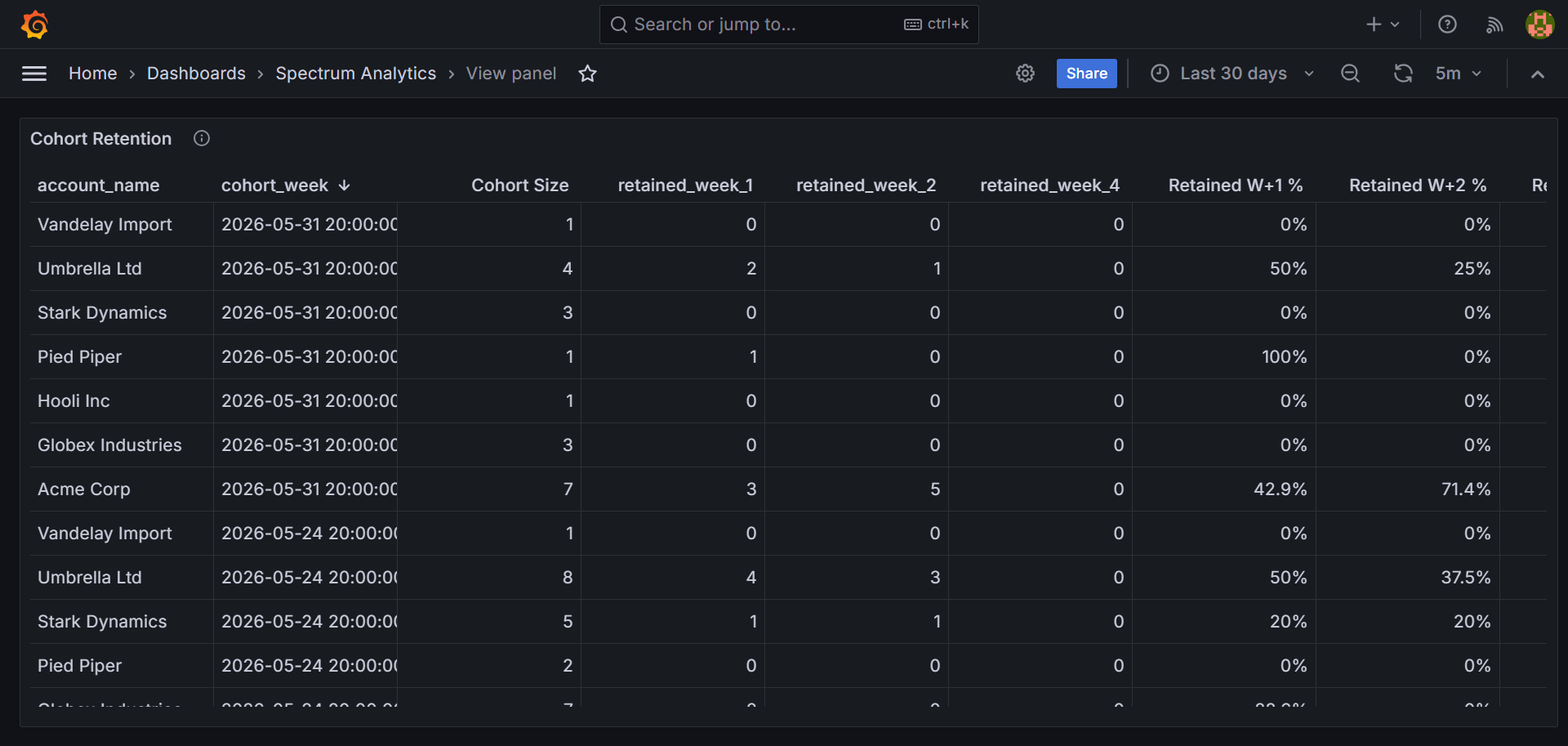
The warehouse layer is a star schema: fact_events in the center, four dimension tables around it. This is build log 04: the DDL, the partitioning strategy, and the index choices and their reasoning.
// 01 — THE FACT TABLE
CREATE TABLE warehouse.fact_events (
event_id UUID NOT NULL,
event_hash TEXT UNIQUE NOT NULL, -- deterministic dedup key
account_id UUID REFERENCES warehouse.dim_accounts,
user_id UUID REFERENCES warehouse.dim_users,
geo_id INTEGER REFERENCES warehouse.dim_geography,
event_type_id INTEGER REFERENCES warehouse.dim_event_types,
occurred_at TIMESTAMPTZ NOT NULL,
event_month DATE NOT NULL, -- partition key
properties JSONB
) PARTITION BY RANGE (event_month);event_hash is the idempotency key: MD5(event_id || account_id || occurred_at). The ON CONFLICT (event_hash) DO NOTHING on insert means re-processing an event is a no-op.
properties is kept as JSONB rather than typed columns because event shapes vary. I’d rather deserialize in the analytics query than maintain a wide schema.
// 02 — MONTHLY PARTITIONS
-- created dynamically by Phase 1 of the pipeline
CREATE TABLE warehouse.fact_events_2026_05
PARTITION OF warehouse.fact_events
FOR VALUES FROM ('2026-05-01') TO ('2026-06-01');Partitioning by month means:
- Queries filtered by date range (
WHERE occurred_at BETWEEN ...) scan only the relevant partitions via partition pruning. - Retention queries that join fact to itself across months (
W+1,W+2,W+4) scan only the two or three partitions involved. - Old partitions can be detached and archived without touching the live table.
Monthly granularity was chosen over daily because at current event volume, daily partitions are too granular (too many small tables) and yearly partitions are too coarse (no pruning benefit within a year).
// 03 — THE DIMENSION TABLES
-- representative example
CREATE TABLE warehouse.dim_accounts (
account_id UUID PRIMARY KEY,
account_name TEXT NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW()
);Dimensions are deliberately small: account, user, geography (country/region/city), event type. Each has a surrogate key the fact table references. Upserts use ON CONFLICT DO UPDATE to keep dimension values current as they evolve.
Geography uses UNIQUE NULLS NOT DISTINCT (country_code, region, city) to handle events where only country_code is known, a PostgreSQL 15 feature that treats NULL = NULL for uniqueness.
// 04 — THE INDEX STRATEGY
-- per partition, created alongside the partition itself
CREATE INDEX ON warehouse.fact_events_2026_05 (account_id, occurred_at);
CREATE INDEX ON warehouse.fact_events_2026_05 (user_id, occurred_at);
CREATE INDEX ON warehouse.fact_events_2026_05 (event_type_id);The analytics queries have three shapes:
- Funnel / retention: filter by
account_id, scan forward in time:(account_id, occurred_at). - User-level retention: filter by
user_id, scan forward:(user_id, occurred_at). - Event-type aggregation: group by
event_type_id:(event_type_id).
All three are covered without a composite index that spans all four columns. Each partition gets its own copy, since partition-local indexes are smaller and faster to build than a global index across all partitions.
event_hash already has a UNIQUE index (from the constraint), which doubles as the dedup lookup.
// 05 — WHAT I SKIPPED
No covering indexes, no partial indexes, no BRIN. At current data volume, the above set is sufficient. I’ll add more as query patterns emerge from the dashboards. Indexes added speculatively are rarely the right ones.
NEXT
- Build log 05: funnels, retention, and revenue as pure SQL against the star schema.
